


Most enterprises still try to use paper-based principles to manage the digital era. This won’t work with the growing volume, variety, and velocity of information. 80% of information is unstructured, and we need to automate how important content is identified, captured, analyzed, and governed. Only then can we turn information chaos into opportunities.

The Building Blocks of Content Analytics
Content Analytics gives you five basic methods or building blocks for analyzing or working with text-based information:
- Grammatical Concept Extraction
- Entity Extraction
- Rule-Based Categorization
- Text Summarization
- Dynamic Categorization Classification
Each of these is a tool you can work with to automate information management. In most cases, you’re going to leverage more than one of these methods to solve your business problem.
Method 1: Concept Extraction
The first method is concept extraction. Concepts are not the same thing as words or keywords, but rather a human-defined concept that makes sense and has a specific meaning. Concepts can represent many things – in fact, almost any idea or entity.
Concept extraction involves defining and describing the “thing” and then building the rules to extract it from a body of text. This is different from identifying a concept in structured text. When we talk about extracting concepts, we’re not only referring to “keyword” discovery and tagging using frequency analysis but rather the ability to accurately recognize a human-defined concept and extract it from a context.
Extracting concepts from text involves both rigorous definition of the concept and the capability to extract it as a distinct entity from text.
Some possible applications;
- Analyze the gender balance of text in a discipline (pronoun references)
- Understand the sentiments of a safety report (adjectives, adverbs)
- Understand whether the language of managers is tempered or highly strung
- Understand the type of actions that are commonly referenced in a community of practice (verbs)
Method 2: Entities Extraction
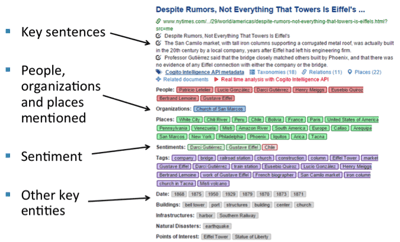
Entities can be anything. They can be named entities – typically proper nouns and specific to a context or application. They can be event entities – typically verb or noun phrases also specific to a context or application. Or, temporal entities – numerals, proper nouns, specific phrases which are general and universal – or numerical entities – general in their form but must be interpreted based on context ($6, 6 cm., 6%).

Here are just a few examples of the entities you can extract from text using this method. Loan numbers, credit numbers, report numbers, trust fund numbers, URLs, phone numbers, document object identifiers – anything that has a predictable pattern.
- Organization Name (companies, NGOs, IGOs, governmental organizations, etc.)
- People Referenced
- Loan #
- Credit #
- Report #
- Trust Fund #
- ISBN, ISSN
- Document Object Identifier
- URLs
- Phone numbers
- Street Addresses
- Statistical Indicators
- Company Symbol/Ticker
- Financial indicators
- Economic indicators
- Medical conditions
- Legal decisions
Method 3: Rule-Based Classification
Rule-based classification implies that we have a scheme and defined classes to which to assign entities or objects. This is a different process than one that uses text analytics to define classes.
Automated categorization is an ‘inferencing’ task- meaning that we have to tell the tools what makes up a category and then how to decide whether something fits that category or not. We have to teach it to understand as much about each class as a person would know. For example, when I see terms like access to phone lines, analog cellular systems, answer bid rate, answer seizure rate – I know this should be categorized as ‘telecommunications.’
Why do we want to use automated, rule-based classification methods? What is the value? There are several possible goals for automating a currently manual classification process.
- We might have a large number of documents or transactions that need to be classified in a short period of time and objectively.
- We might need a more reliable or accurate classification that is possible with manual methods.
- We may need to classify more deeply or extensively than is affordable using manual methods.
- We may need to evaluate reports or documents to better understand how they align with a framework.
One of the most important tasks is constructing your pre-defined classification scheme. In some cases, you may have rich descriptions of the classes. In other cases, you may have a structure but lack deep conceptual descriptions of each class. If the scheme exists, we have to understand its underlying structure and the definitions and focus of each class. Each class must have a deep description that the machine can use to “understand” and make selection decisions. If the scheme is new, you can develop good definitions of each class and build out those definitions using semantic and text analytic methods.
Method 4: Text Summarization
In a world of information overload, the need for summaries is high. Some machine summarization methods produce sentence fragments. These extracts generally rely on frequency counts and pattern matching. They may or may not have an underlying semantic or language foundation. The more sophisticated tools will allow you to define the rules for identifying and selecting whole sentences for the extract, for defining how many sentences, and how to order them.
Method 5: Dynamic Categorization Classification
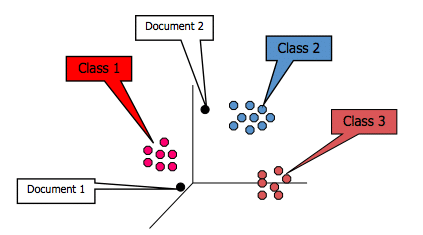
We primarily use dynamic classification methods when we are interested in:
- Discovering something about the nature of the data set – either as an end in itself or as a first step to a semantic solution
- Predicting future events based on patterns we see in text, and establishing or exposing hidden relationships among concepts in the data set.
The heavy lifting of dynamic classification is getting us from the raw unstructured text to something or some form that we can use for the application of statistical tools. This is in lieu of applying human knowledge to the text. We have to turn the text into something that looks more like structured data.
While the overarching method is statistical, we can add semantic or linguistic aspects to this approach with some tools. Some commonly used clustering methods include K-Nearest Neighbor, Bayesian Networks, Neural Networks, Support Vector Machines, and Decision Trees. The reason we take a dynamic approach is generally because we want to understand something about the unstructured text before we apply human knowledge to it.
Use Cases for Content Analytics in Information Management
Let me give you a few examples of how this can improve your information management.
Security & Privacy - 74% of AIIM members think information security, privacy, and compliance should be inherent and transparent to the knowledge worker. Analytics will help us achieve this, but also make it more granular and consistent. Most security models focus on managing the container, not the actual content. We secure information based on content type, e.g., HR files and customer contracts. Analytics allows us to secure information based on the actual content. This means staff can be told that they can’t send this email or attachment since they have written about confidential stuff, or that they can’t copy/print this text when they try to do that at a MFP.
Information Compliance- 81% of industry professionals realize that Information governance will never work without ways to automate how information assets are identified, captured, analyzed, and governed. AIIM’s latest AIIM Information Governance Industry Watch also asked people about their overall plans for automated declaration/classification of records:
- 24% We have no plans
- 63% we are just getting started or plan to do in the future
- 14% We are already doing it successfully
Scanning & Capture - Analytics will allow us to get an accurate and consistent summary and metadata of everything we scan or capture of new information. It will allow us to quickly understand what the email attachment or scanned document is about. The revolution in smartphones will also soon allow us to add this to augmented reality, e.g., You hold your phone camera over some text, and the phone captures the information using OCR and analytics to tag and summarize the document. This information is then shown in realtime on the smartphone screen on top of the text, which will allow to quickly find what you are looking for.
Search - Improving search is one of the top priorities among AIIM members, but search is usually linked to an application or problem like compliance and eDiscovery. It’s often about finding information without knowing what’s available. We need to be guided to the best result with faceted navigation and results. Gartner consider analytics to be key for improving access to information, and they predict that smart computing and analytics will rejuvenate the enterprise search market in 2014-2017. From Gartner Magic Quadrant for Search 2014: “In 2013, we saw the Nexus of Forces – social, mobile, cloud and information – affect the information-centric enterprise search market substantially….”.”…. we see an increased drive for contextualization. Organizations are no longer satisfied with a list of search results – they want the single best result”.
Personalization & Recommendations - The 2014 Gartner Magic Quadrant for Enterprise Content Management doesn't stress the importance of analytics, but it still claims that by 2016, content management will be personalized, with foldering and process needs tailored to each individual user. Analytics has an important role to play with this, but also for providing customers and employees with recommendations. Staff should become aware of other relevant information and knowledge, - e.g., a sales rep writing a proposal should be aware of other relevant proposals. This will improve knowledge worker productivity, but also customer service and profitability. Amazon claims 35% of its revenue comes from recommendations. Customers need help finding what’s right for them.
Insights - 91% of information and IT professionals think semantic and analytical technologies are key components for turning information chaos into information opportunities. We can use analytics to better understand staff, customers, and competitors, which will help us predict the future. The below picture shows Santa Cruz PD - they use historic information to predict crimes. They can then deploy officers to this area ahead of crime, which helps them improve productivity.
Conclusion
The convergence of mobile, social, and cloud computing is creating a perfect storm for information management. Analytical and semantic technologies allow you to turn information chaos into information opportunities. Reduce costs, manage risks, add value, or create a new business opportunity using analytical and semantic technologies.
