


I find the auto-complete functionality in Google fascinating.
What I am referring to is when you type in a few words, and the Google algorithm predicts what you might be interested in based on your own behaviors and that of the universe at large. It’s actually more fun if you log out of your own Google account first to get a less biased result so that you can get a true sense of what is on the mind of your fellow citizens.
For example, if I start typing “I have a problem with,” Google promptly offers this assistance:
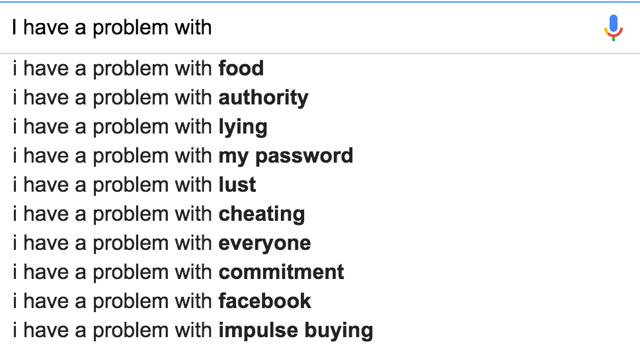
This is a rather fun game. Try it. Here are the results for “John Mancini.” I am glad for the 3rd result and also pleased to note that I have never been to Youngstown, OH.
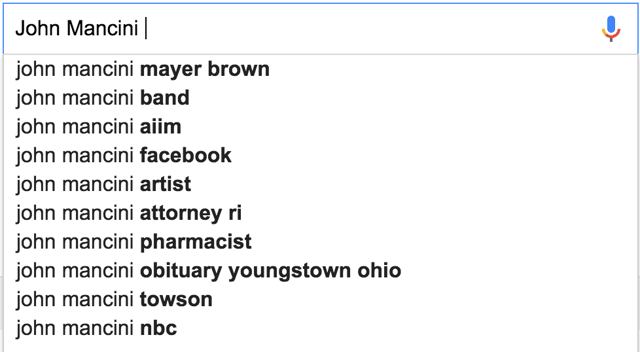
The reason I bring this up is that the algorithm is essentially offering up words and phrases that go together, based on a huge pool of data and interactions.
In everyday life, sometimes this is useful – it creates a shorthand that allows us to speed communication. However, at other times – especially when terms and language are changing rapidly – it is reactive – backward-looking – rather than predictive.
I think about this often as I talk with “capture” vendors and customers for “capture” products. Because we all have used the term “capture” for so long, the phrase is almost always with automatically or implicitly expanded to be “scanning and document capture.”
Now in some ways, that’s OK. Because while traditional “capture” technologies have been around a long time, this is still a relatively immature market with lots of opportunities, especially among small and medium-sized organizations. At AIIM, I am constantly amazed at the demand for what I would call “Document Capture 101” content. At times it feels like I’ve fallen into a black hole and arrived back in 2002.
Capture Needs a Makeover
But the term “capture” now needs a makeover to take the next step. “Capture” – or some other descriptor -- needs to assume a much wider meaning in the disruptive world into which we are headed.
A world in which not only documents, but all kinds of information are being captured.
A world in which all the information we capture – or have captured in the past – is put into motion and becomes a rich source of intelligence, insight, and potential customer value.
A world in which customer and process information is being captured closer and closer to the point of its creation.
A world in which the “image” being captured is the least important part of the value equation.
A world in which information capture – intelligent information capture – becomes the key enabling technology for digital transformation, and sets the stage for the machine learning revolution.
