


We once had an IT person who worked for us who took a page out of the old Saturday Night Live routine, Nick Burns -- Your Company’s Computer Guy, who guarantees to “fix your computer and then make fun of you.”

When one of us would bring to light an error that was obviously our fault, this fellow would confidently pronounce, “That looks like a user ID-10-T error,” at which point we would slink off, afraid to acknowledge that we didn’t know what an ID10T error was.
I will admit that I have also reused this joke many times on the unsuspecting.
We’ve been through a time in which many content management best practices -- for example, the ability to assign records categories and corresponding retention periods -- have existed, but required some sort of user action actually to make them happen. Which meant that they never did. Thankfully, auto-classification and the automatic linking of document types to retention periods are taking information governance out of the hands of individual end-users, who always resented the Nick Burns of the world, telling them that they should somehow find time to “care” about records management.
A variety of Nick Burns characters have also long lectured on the importance of metadata. Metadata is another area in which we’ve all had unrealistic expectations that users would help us with this key task.

In the spirit of any good self-help group, I have a confession at this point
“I’m John Mancini, and I have neglected my metadata responsibilities. I want to share my story with the group.”
I do a lot of guest posts for all sorts of publications and vendor blogs— a lot. So sometimes, I lose track of exactly what I have done and when.
This week, I was beginning work on a post and recalled some similarly themed posts that I had done two years ago for another client. When I do blog posts about a particular topic, my first step is to do a pretty comprehensive information gathering through Google, and then usually just use a tiny portion of the information in the final post. So I thought there might be some good raw material that I could draw upon from two years ago for the new post.
To make a long story short, I came upon not only raw material but a REALLY good draft post on exactly the right topic that I didn’t remember ever publishing. But had I? I really didn’t want to make the mistake of publishing something as new that I had already published. How could I figure out whether I could actually use this post?
First stop, I searched some of the keywords in the post on the client site for whom I would have published the post two years ago— nothing there. So far, so good.
Next stop, I noticed the date on the file, August 4, 2016. If I had published the post, there would likely have been some sort of approval email chain around that time. I checked my admittedly “retention policy-inconsistent” sent-mail file (confession is the first step on the path to redemption, see above records management comments); nothing there.
OK, how about I tap into Google’s incredible cognitive power and take an unusual phrase from the post and see if it pops up anywhere? My eye just randomly strayed to a phrase in the document, “Do our systems weed out and eliminate information I don’t need to see?”
I popped it into Google with the following search results. I should note for the official record that I was NOT signed into Google at the time, so these results were not cognitively generated based on any search or personal history. Really.
So I then had an epiphany, based on my more than two decades of experience in the document management space.
Let me just look at the document properties and metadata and revision history!
And the results?
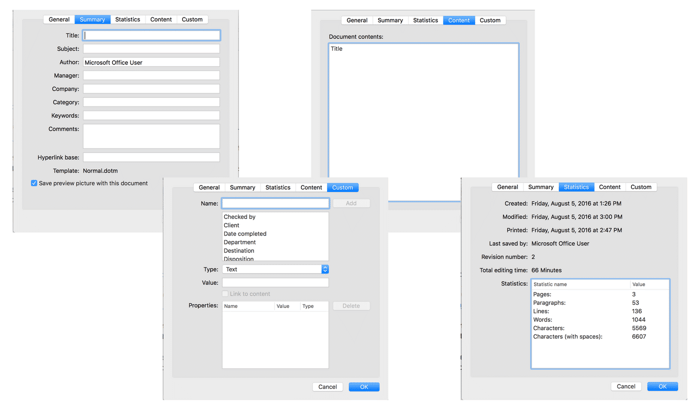
Revenge of the metadata nerds!
It doesn’t have to be this way. On your future-facing content management wish list ought to be these kinds of capabilities:
- Automatic assignment of metadata at the point of creation based not on the folder or repository where it is stored, but what it is.
- Cognitive agents that actually understand the contents of a document and automatically assign metadata.
- Automatic rights management is independent of the means of transmission that requires no conscious user action to track where a document goes, who looks at it, and what they do with it.
