


It’s bad enough that those of us in the technology space use three-letter acronyms as if we’re being paid per usage. So here's a quick definition of terms for those mystified by the title of this post. If you are not conversant in Dr. Doolittle (even the Eddie Murphy version), Pushmi-Pullyu is a "gazelle-unicorn cross that has two heads (one of each) at opposite ends of its body."

Many of you are aware that I’ve been working on a personal mystery project on the weekends that I’m publishing on Medium titled In Search of my Grandparents: A records management journey.
In the process of working on this personal genealogy project (especially on the Ancestry.com platform) and simultaneously doing a bit of work for a company called Preservica, it has struck me that there is a profound technology duality at play when it comes to long-term information preservation.
On the one hand, technology has revolutionized both the access and potential value of very long-term archival information -- much of which originated as paper -- exposing it to the light of day after years in the basement and giving it new life.
And on the other hand, rapid and escalating technology innovation and the accumulation of ever-increasing cascades of digital information -- usually with no thought to how access will be preserved for future generations -- is creating a worrisome digital preservation scenario. Much of the world’s cultural, economic, social, and political memory is at some long-term risk. Will this information be available and digestible 75 years from now?
Hence my Pushmi-Pullyu analogy, with one technology head pulling us in one direction (It’s the best of times for preservation! We have access to so many things we never did before!), and the other technology head pulling us in another (Oh my gosh, will our grandchildren have access to anything we’re currently doing?).
True confession, one of the reasons this all bothers me was that I started life as a history major.
Pushmi Effect: Old information gets new life and becomes available to more people than ever before.
My interest in genealogy, while amplified by some recent revelations on my father’s unknown side of the family, actually goes back over twenty years, and thus I’m in a good seat to understand how dramatically things have changed in the past two decades. Ironically, about the same time that I've been at AIIM.
It all started with my mother-in-law, Nancy. It turns out that Nancy had relatives going back before the Revolutionary War. When you come from immigrant grandparents and with family knowledge very limited beyond that, the opportunity for a history major to do a bit of research on a family with known (albeit a bit vague) roots that date back before the Revolutionary War was compelling.
Nancy had silver knives, forks, and spoons with initials that went back to the early 1800s, for crying out loud. And to boot, after years of training in studying this silver, my wife could rattle off a pretty sweet litany documenting her mother’s side of the family at the drop of a hat. “My mother was a Sowers; her mother was a Stull, her mother was a Davis, her mother was a Baylor, her mother was a Glen, her mother was an Abernathy, her mother was a Samuels.” Contrasted in my case too, “My mother was a Manson, her mother was a McEvoy, and errrr….that’s all we know.”
The specific thing that got me going on this family research kick was a picture that Nancy had of herself when she was two years old with her grandfather -- a fellow named Caleb Sowers. Of whom she said, “Well, he was a drummer in the Civil War, and he was buried in his Confederate uniform, but I don’t know much more than that.” That was enough to get me going.

Of course, this was all back around 1995 -- about the time I joined AIIM -- and family research was a far different kettle of fish than it is now. In 1995, if I was going to find this Civil War fellow, it meant a personal trip to the National Archives through the microfilmed military records.

It also meant some posts to alt.war.civil newsgroups. Why didn’t I just do a web search? HaHaHa. Web access and browsing were still pretty much the province of techno-nerd types and a couple of years in the future for anyone beyond that.
I recently found an initial communication dated May 12, 1995, to this newsgroup. It had the supercool email address 76446.2252@compuserve.com@internet. Sweet.
It feels all so Indiana Jones-ish now.
I remember the first time I went to the Archives. Rows upon rows of microfilm tapes, generally organized and indexed, but largely dependent upon the users to find the right tape, fire that bad boy up, and starting rolling through images until you found about the right place on the tape -- and hopefully the right image.
For the benefit of my younger readers, spoiled by the web, here’s what these contraptions looked like. And by the way, in case I ever forgot to mention this, we used to also walk 6 miles back and forth to school when we were kids. In the snow. Even in summer.

After a bit of searching, I found out that this Caleb fellow served in the 24th Virginia Infantry, Company A, known as the Floyd [VA] Rifleman. He enlisted on May 16, 1861, and was captured in 1865, almost at the end of the Civil War, at the Battle of Five Forks (outside of Petersburg). This unit certainly took its licks in the war. Of the 83 men who enlisted at the beginning of the war with my wife’s great grandfather, and another 85 who enlisted later in the war (168 total), 61 died during the war and 39 were wounded. The high mortality rate was not terribly surprising given that the unit was part of the battles of Williamsburg, Seven Pines, 2nd Manassas, Drewrey’s Bluff, and most notably, Gettysburg. Not only Gettysburg, but just to make it extra fun, Pickett’s Charge at Gettysburg (on the right wing).
While all of this laborious, pre-Internet, manual document search was going on, a technology revolution was brewing, one that AIIM and a lot of my new AIIM friends were leading. The evolution of Ancestry is probably as good a metaphor as any for the revolution that allowed previously unknown snippets of paper-based information to become digits and in turn become available and searchable in a fashion previously unimaginable.
Ancestry -- minus the .com in their name -- was started as Ancestry Publishing in 1983, publishing over 40 family history magazine titles and genealogy reference books. The .com was added to their name in 1996, and they began publishing family history information on CD-ROM (remember those?) in 1997.
Three technology waves collided to dramatically transform the genealogy value proposition for Ancestry -- and frankly, the entire value proposition for historical archives.
First, a revolution occurred in our industry -- the image management industry. This was a revolution in the ability of machines (computers) to help understand all of the information that was preserved -- but difficult to access -- on microfilm. Up until the past few decades, indexing all that information on microfilm was a pretty manual affair requiring human indexers. As OCR (Optical Character Recognition) and ICR (Intelligent Character Recognition) technologies improved, and as microfilm images were converted to digital images, it became possible to automate -- in part -- the indexing of all of those microfilm images and automatically extract more information from them than ever before. This was particularly the case with information that was textual and structured, like an obituary or a ship's manifest or a census record.
Secondly, the wave of consumer and web technologies suddenly removed the need for all of that physical media like floppies and CD-ROMs, and brought information directly into people’s homes. It also allowed companies like Ancestry to expose all of those images freed up by the revolution in computer indexing to millions of customers, who then added human value and interpretation to them. As the number of people on a particular platform (like Ancestry, for example) and their associated records kicked in (people started posting images and making their family trees available to others), the network effect (the phenomenon whereby a product or service gains additional value as more people use it) dramatically increased the quantity of information available. (Not to mention the addition of DNA information to all of this.)
Lastly, enter big data technologies to help link all of this together. Technologies like Hadoop and MapReduce provided machine linking of information, allowing companies like Ancestry to move beyond proprietary technologies and leverage the power of the network.
To put all of this in perspective, consider the following data points about Ancestry.com:
- More than 20 billion records have been added to the site over the past two decades, and Ancestry adds an average of two million records to its website each day.
- Ancestry members have created 90 million family trees containing more than 10 billion ancestral profiles and have uploaded and attached more than 330 million photographs, scanned documents, and written stories to their trees.
- Ancestry subscribers have made more than eight billion connections between their trees and other subscribers’ trees since the feature was added to the site in early 2008.
- Ancestry has over 15 billion U.S. records on its sites.
- Ancestry hosts records from over 80 countries worldwide.
- Ancestry.co.uk hosts the UK’s largest online collection of family history records with more than one billion searchable records.
- Ancestry currently manages about 10 petabytes of structured and unstructured data, including billions of records detailing births, marriages, deaths, military service, and immigration.
The Pushmi Effect of accelerating technology innovation has opened up new tools to access information preserved long ago, but heretofore unusable.
Pullyu Effect: Digital information is being created at such a pace and volume that its long-term availability is in question.
We recently did a bit of research on this question of the long-term survivability and sustainability of digital information. Every organization -- across all sectors and geographic boundaries -- has critical digital information it needs (or wants) to keep for 10 years or longer, often for decades or even permanently - from core business information to assets for industry specific regulation.
Organizations have very good intentions when it comes to managing this information -- 76% of organizations see digital preservation as “very important” or “important” and a critical part of their Intelligent Information Management strategy.
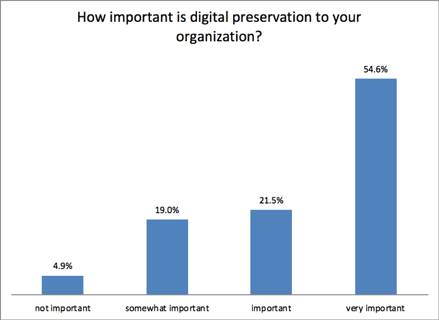
And yet...Note the percentages of organizations that agree with the following statements:
- 79% - “Digital information that must be kept for 10 years or longer is inherently at risk due to changes in technology and file formats.”
- 75% - “Digital records are at constant risk of not being findable, readable or useable when required.”
- 64% - “Ensuring the readability of digital information in the future is an afterthought for us.”
In the pre-digital era at AIIM, microfilm did a pretty good job of taking care of both the short-term information utilization needs of many organizations (better, faster, cheaper, easier to manage than paper) and their long-term information preservation needs (eye-readable for more than 500 years).
These two information management objectives - utilization and preservation -- got separated along the digital journey. In the process, long-term preservation of digital information took a backseat to the short-term utilization and optimization of this information in business processes. In addition, many organizations lost track of the key differences between back-up, archiving, and true long-term preservation.
The business implications of the failure to ensure access and usability of long-term digital information are significant. This failure is impeding the ability of many organizations to extract value, mitigate risk and use information in an intelligent way for competitive advantage.
Organizations have an accumulated information risk from the past 30 years of digitization that now must be addressed retrospectively. Organizations are now reconsidering all of the many information repositories that exist and the information they contain, and struggling with fundamental questions of what to save, how long to save it, and in what form. It's particularly a challenge as the generations of content management systems shift and organizations struggle with how to retire legacy systems -- without losing the information those systems contain.
The Pullyu Effect of accelerating technology innovation is increasing information chaos, especially when it comes to preserving information for the long-term. That needs to change.
