

Document Management | Automation | Artificial Intelligence (AI)
Having your cake and eating it, too, is a proverb that’s almost 500 years old, which means you cannot have two incompatible things at the same time.
So many examples of situations exist where you face two mutually exclusive options. Let’s take document capture. Document capture software is designed to automate document-oriented tasks such as sorting or extracting key data. In order to achieve that automation, you must spend time to configure the software to identify documents and reliably locate and extract that data with a high enough degree of accuracy that your staff need only be involved in verifying a small percentage of it.
Achieving High Accuracy STP
Generally, getting to the expected level of performance, typically above 80% straight-through processing (STP) automation at accuracy levels equal to—or better—than a human takes a significant amount of time. First, the staff must learn how to use the software and then design the rules required to automate. Lastly, they must analyze the results and make adjustments.
Depending upon the complexity of a document, such efforts can easily exceed several hundred hours for one type of document. For simple structured forms, even though the layout doesn’t change, variance in quality can require analyzing several hundred examples in order to build rules that are flexible enough to perform. For unstructured data such as invoices, receipts, or bills of lading, to build a reliable set of rules requires analysis of potentially thousands of variants.
Configuration and Operational Simplicity
Another expectation is also associated with document capture: it must be simple to configure and operate. As illustrated above, achieving a high-level of performance is definitely not simple. This is one reason why expenditures on professional services can easily reach two to three times the cost of the software license itself. Regular statistical measurement and tuning of performance represents an ongoing expense.

Simply put, advanced document capture has not been scalable when it comes to performance: the more complex the document type and the higher the performance, the more expensive and less-simple the solution. If we were to plot dichotomy on a graph, it might look something like this:
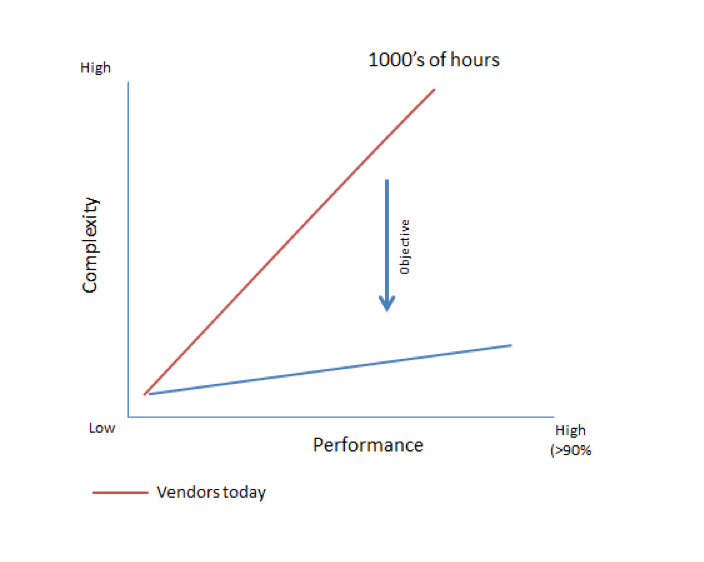
The objective of any document automation solution should be to lower the slope of the “complexity/cost” line. In doing so, organizations can enjoy high performance without the high cost or complexity. The result is that organizations have to make a tradeoff. They adopt advanced capture and spend a lot to achieve performance; or they make-do with suboptimal performance; or they don’t adopt advanced capture at all.
In the world of advanced capture, is there having your cake and eating it, too? With the continuing evolution of machine-learning-based AI, isn’t there a way to further advance document capture? The answer to both questions is “yes.” After all, Google provides a visual search allowing us to find images similar to what we upload so deep learning can accomplish something similar for document classification and extraction. The goal is to produce an AI, which can be trained to sort documents and data as more effectively and faster than humans. The ideal graph using “artificial general intelligence” would look something like this below.
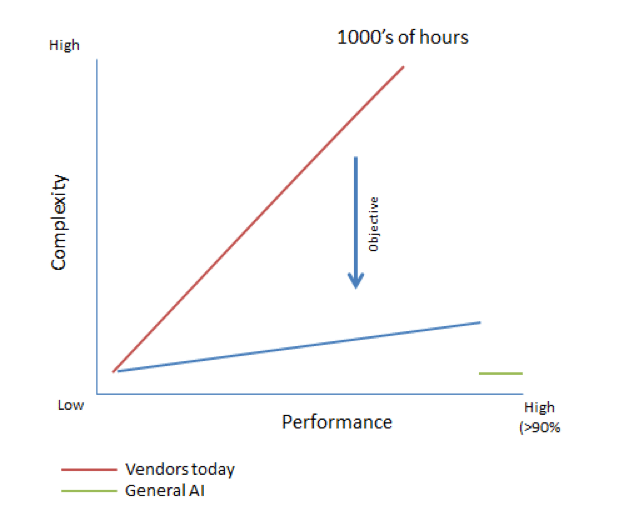
Such a graph represents shows the effort to train an AI, which is similar to a human and, once trained, is highly adaptive and can perform at traditionally high levels of human accuracy (generally above 90%).
Advanced Applied AI Systems
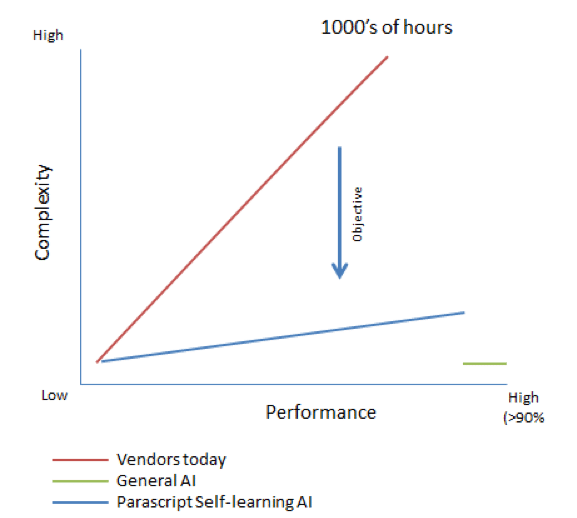
In reality, artificial general intelligence systems cannot achieve this. However, that doesn’t mean that high-performing systems cannot be achieved with low effort. Using the latest advancements in machine learning theory, we can use a system similar to IBM Watson to train a system to “understand” document types, to locate data and even to adapt to mistakes or changes in data. We call this “self-learning” and it is the basis of Parascript’s new FormXtra.AI platform. An organization no longer needs to spend time learning how to use the software or to configure, tune, and maintain it. Rather, you only need to “feed” it data on which to learn. This capability produces a graph where performance still does not achieve artificial general intelligence but does reach high levels of performance over today’s expensive, complex, manual and, brittle rules-based methods.
The same self-learning platform easily calculates performance and can automatically adjust output to achieve a specific, required accuracy level. If your organization requires 95% accuracy, it can identify the ideal break-point for each data element. This additional automatic optimization produces a graph like below.
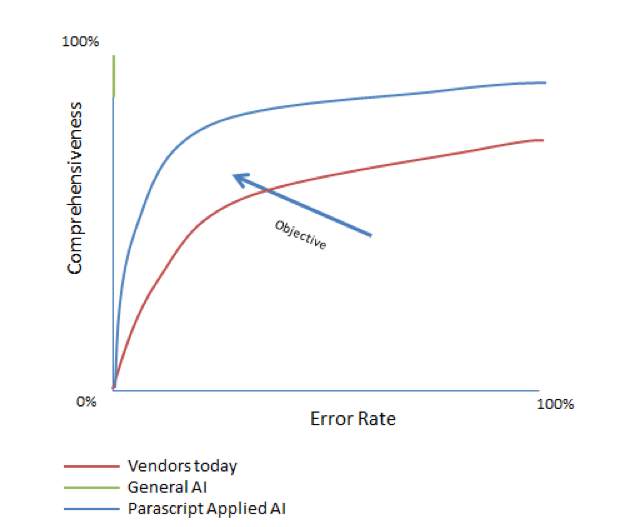
With this new system, the software can automatically identify good data from bad and adjust the threshold that allows data to run straight-through with zero manual intervention. The result is the highest level of automation, but without the typical fortune required to achieve it. This is the promise of using advanced machine learning.
With advanced applied AI systems, it is possible to have your cake and eat it, too.
